Hotel Recommendation Using Word Similarity in Tags and User Searches
- Published on
- • 6 mins read•––– views

Sometimes it's tough to figure out what users actually want when they search for something. So to solve that problem, in today experiment We will working on a hotel recommendation system that uses cosine similarity to better understand what users are looking for. Cosine similarity helps us measure how similar a user's search is to various hotel tags. By doing this, we can offer more precise and fitting recommendations. Our goal is to improve the user experience by suggesting hotels that closely match their search intent and desired features.
We also use google colab as our platform today. So, let's jump in!
1. Gather Dataset
In this experiment, we will use dataset from Kaggle. You can run all the syntax below to gather the dataset.
import os
os.environ['KAGGLE_CONFIG_DIR'] = '/content'
Before you run the next syntax you need to upload your kaggle.json to the google colab, you can see this tutorial on how to get the kaggle.json file.
!kaggle datasets download -d jiashenliu/515k-hotel-reviews-data-in-europe
!unzip \*.zip && rm *.zip
2. Import Library
import pandas as pd
import numpy as np
import nltk
nltk.download('wordnet')
nltk.download('punkt')
nltk.download('stopwords')
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem.wordnet import WordNetLemmatizer
Print dataframe head
df = pd.read_csv('Hotel_Reviews.csv')
df.head()
3. Preprocessing Dataset
Check dataframe detail information
df.info()
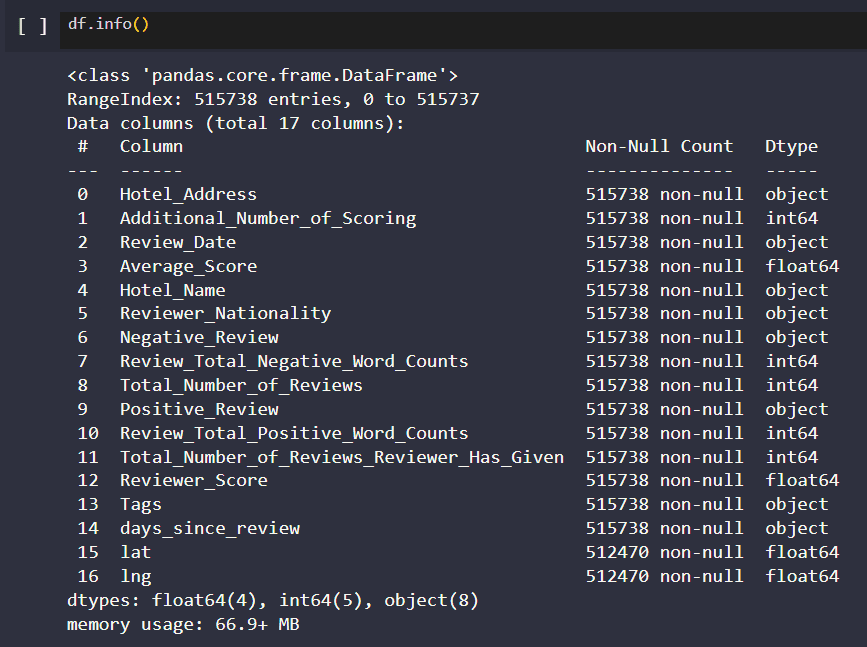
Your output should look like the picture above. The next step is to lowercase all the column name. This is done because some columns are capitalized in the first word while others are not.
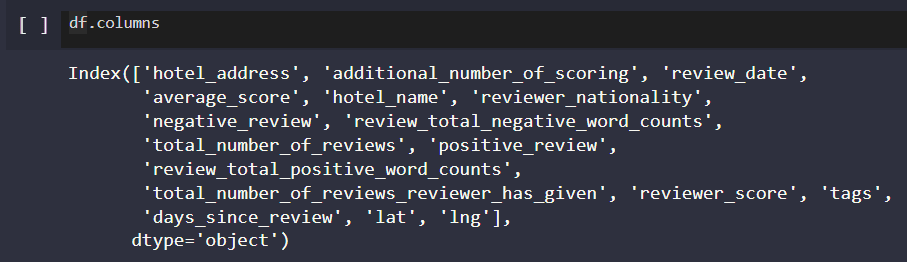
df.columns=[x.lower() for x in df.columns]
df.columns
Next we will drop columns that are not needed in this experiment, such as review. We only use tags in today experiment.
drop_columns = ['additional_number_of_scoring',
'review_date', 'reviewer_nationality',
'negative_review', 'review_total_negative_word_counts',
'total_number_of_reviews', 'positive_review',
'review_total_positive_word_counts',
'total_number_of_reviews_reviewer_has_given',
'reviewer_score', 'days_since_review']
df1 = df.drop(columns = drop_columns, axis = 1)
df1.head()
Null and duplicate value will ruin our model, so we will drop all rows with null and duplicate values. IT IS ADVISED not to fill this null value, because the null is in column lat and lng. These columns depend on the real coordinate, so we can't replace them.
df1.isna().sum()
df1.dropna(inplace = True)
print('Duplicated data:', df1.duplicated().sum())
df1.drop_duplicates(keep = 'first', inplace = True)
hotel=list(df1['hotel_name'].unique())
len(hotel)
This should print 1475
Next we can see that there are some row that contains "H tel" instead of "Hotel", so we will fix this.
df1[df1['hotel_name'].str.contains("H tel")]['hotel_name'].unique()

df1['hotel_name']=df['hotel_name'].apply(lambda x:x.replace('H tel','Hotel'))
Now we should be good. Next we also want to change word "United Kingdom" to "UK" to ensure the integrity.
df1['hotel_address'] = df1['hotel_address'].str.replace("United Kingdom", "UK")
Next we will split the address and pick the last word in the address to identify the country.
df1["countries"] = df1['hotel_address'].apply(lambda x: x.split(' ')[-1])
print(df1['countries'].unique())
Output
['Netherlands' 'UK' 'France' 'Spain' 'Italy' 'Austria']
4. Preprocessing Tags
If we look back at our dataset, we will see that tags column is in string type. Well we can not map each tag if their entire tag is in 1 string. So we will fix this by converting it to set.
import string
exclude = set(string.punctuation)
def clean(x):
return set([''.join(ch for ch in i.lower() if ch not in exclude).strip() for i in x[2:][:-2].split(',')])
Next, we apply the func to clean the tags and assigning them to a new column.
df1['tags'] = df1['tags'].map(clean)
Next we will see how are our tags look like now.
tag_sum_list = []
def get_tag_sum_elems(tag_sum_string):
global tag_sum_list
tag_sum_list.extend(tag_sum_string)
return True
for i in df1['tags']:
get_tag_sum_elems(i)
tag_sum_set = set(tag_sum_list)
tag_sum_set
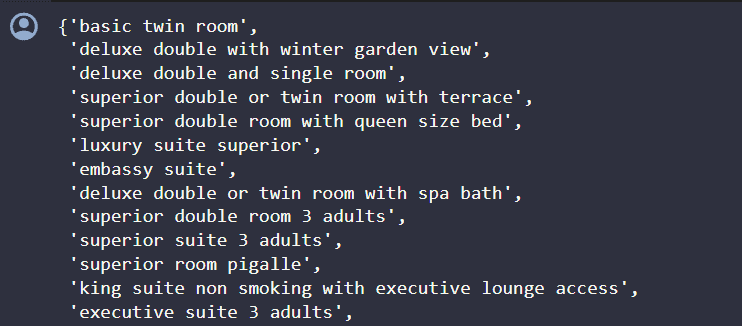
If you pay attention to the output above, you can see there is a tag called "submitted from a mobile device", which is non sense. So we will remove this tag.
def remove_tag(tags_set):
tags_set.discard("submitted from a mobile device")
return tags_set
df1['tags'] = df1['tags'].apply(remove_tag)
5. Make the Model
Now we will make our model. First we will make a function called recommend_hotel that takes an input description and optional data.
- It preprocesses the input by converting it to lowercase, tokenizing it, removing stop words, and lemmatizing the words.
- It then extracts potential location identifiers from the input.
- The function prepares the data by processing the hotel addresses and tags.
- It computes a similarity score for each hotel based on the intersection of its tags and potential location identifiers.
- The hotels are then sorted based on the similarity score and average score, and duplicates are removed.
- Finally, the function returns the top hotel names, addresses, and average scores as recommendations based on the input description.
def recommend_hotel(input_description, data=df1):
# 1
input_description = input_description.lower()
words = word_tokenize(input_description)
stop_words = stopwords.words('english')
lemm = WordNetLemmatizer()
filtered = [lemm.lemmatize(word) for word in words if word not in stop_words and word.isalpha()]
# 2
potential = set(filtered)
# 3
data['processed_address'] = data['hotel_address'].apply(lambda x: set(word_tokenize(x.lower())))
data['processed_tags'] = data['tags'].apply(lambda x: set(word_tokenize(x.lower())) if isinstance(x, str) else set())
# 4
cos = []
for index, row in data.iterrows():
tag_intersection = row['processed_tags'].intersection(potential)
address_intersection = row['processed_address'].intersection(potential)
cos.append(len(tag_intersection) + len(address_intersection))
#5
data['similarity'] = cos
data = data.sort_values(by=['similarity', 'average_score'], ascending=[False, False])
data = data.drop_duplicates(subset='hotel_name', keep='first')
data.reset_index(drop=True, inplace=True)
#6
return data[['hotel_name', 'hotel_address', 'average_score']].head()
6. Use Case
First Example
Now we will use our function to make predictions.
input_description = input("What do you need?\n")
recommendation = recommend_hotel(input_description)
recommendation
Next, we will input out search query
What do you need?
I am going on a business trip on a budget, so I need a classic room for 5 nights in Chelsea, London.
It will output like the picture below.
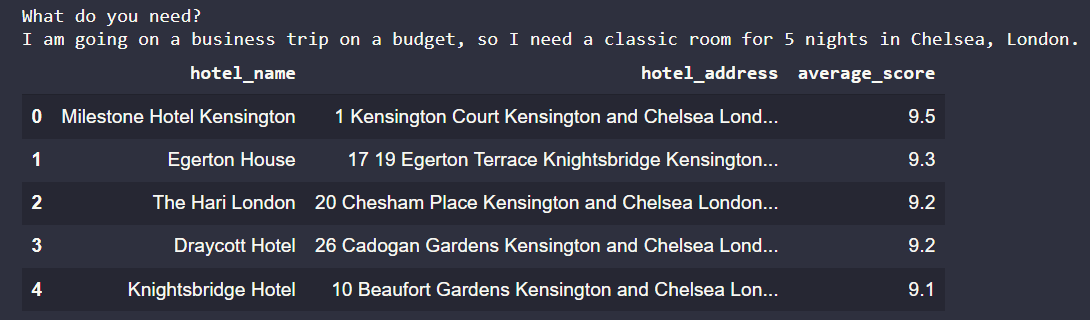
You can see that we get it right, all the hotel places are in Chelsea, London.
Second Example
What do you need?
I am going for honeymoon with my beloved and need a luxury room for 3 nights in Paris.
It will output like the picture below.
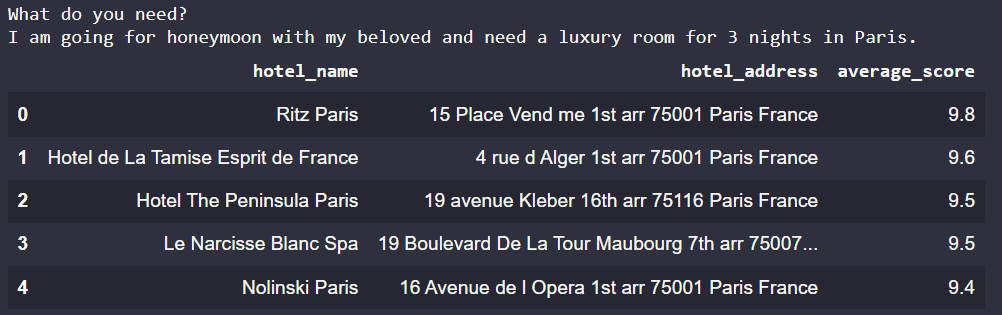
You can see that we get it right, all the hotel places are in Paris, France.
References
Code is made by Ten
Happy DLearn-ing!